

Design principles
The architecture is shaped by a small set of decisions that hold across every layer.Events are the source of truth
Every billing outcome is derived from raw usage events. Those events are persisted redundantly and retained for replay, so any downstream state can be rebuilt from first principles.
Redundancy at every hop
No single component failure causes data loss. Each stage of the pipeline has an independent durable store that absorbs the failure of the stage after it.
Region isolation by default
Every component is region-restricted. Data for a region never leaves it, and each region runs an independent stack.
Self-hostable by construction
The same artifacts that run Flexprice Cloud ship as Helm charts. Every dependency is open source and swappable, so a dedicated deployment is the cloud architecture, not a fork.
System architecture
The platform is fully containerized. A single codebase runs in three modes — API, Consumer, and Background Worker — behind a load balancer, with a private data tier (multi-AZ) and a set of external components for analytics, orchestration, and webhook delivery. Only the API service is exposed to the internet. It sits behind an Application Load Balancer and a WAF in public subnets; every database, broker, and cache lives in private subnets, across multiple availability zones, with no inbound internet route.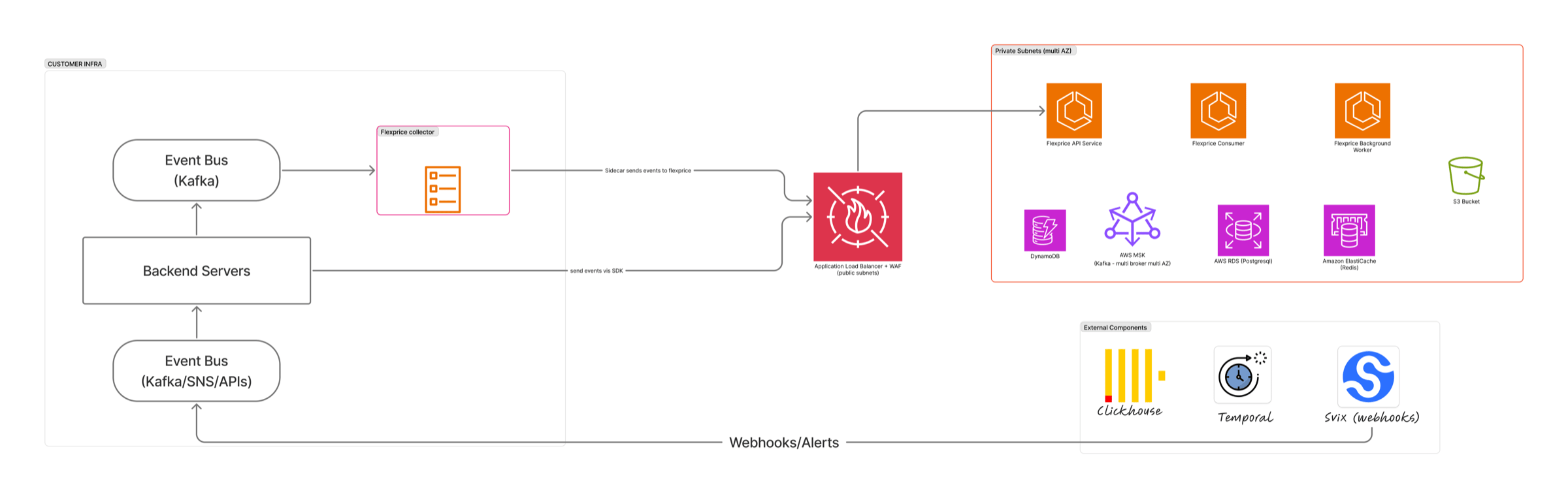
Runtime services
All three services are the same image, started in different roles. This keeps deployment, versioning, and operational tooling uniform.Data stores
Each store is chosen for one job and isolated to it. Every required component has an open-source equivalent that ships in the self-hosted charts. The one managed-cloud service below — DynamoDB — is optional and used only in Flexprice Cloud.DynamoDB is the only managed-cloud component in the architecture, and it is entirely optional. Flexprice uses it in Flexprice Cloud as the most resilient form of data-redundancy store. Self-hosted and dedicated deployments do not include it and require no cloud-specific component — durability is already guaranteed by Kafka’s replayable log, the SDK’s retries, and the S3 degraded-mode fallback.
Event ingestion pipeline
Ingestion is the most infrastructure-heavy part of the system, because it is the part that must never lose data. Everything downstream — balances, invoices, analytics, reconciliation — is reconstructable as long as the events survive.Ingestion modes
You choose how events reach Flexprice based on how your systems are already built.SDK
Server-side SDKs in all popular languages send events directly. The SDK runs in sync mode with configurable retries and fallback handling built in.
Collector (sidecar)
A Flexprice collector runs inside your infrastructure, pulls from your existing event bus, applies custom transformations to your internal format, and forwards to Flexprice.
Direct API
For systems that prefer to call Flexprice directly, every ingestion path is also a plain authenticated REST endpoint.
Ingestion flow
The receive path is deliberately lightweight. The API performs only static validation — a well-formed payload on an authenticated endpoint — then writes the event to Kafka, the durable backbone, before acknowledging. In Flexprice Cloud the API additionally writes to DynamoDB as an optional redundancy buffer; self-hosted deployments rely on Kafka’s replayable log alone. Heavier work (enrichment, aggregation, ClickHouse writes) happens asynchronously off the Kafka stream, so a spike in volume never slows the acknowledgement path.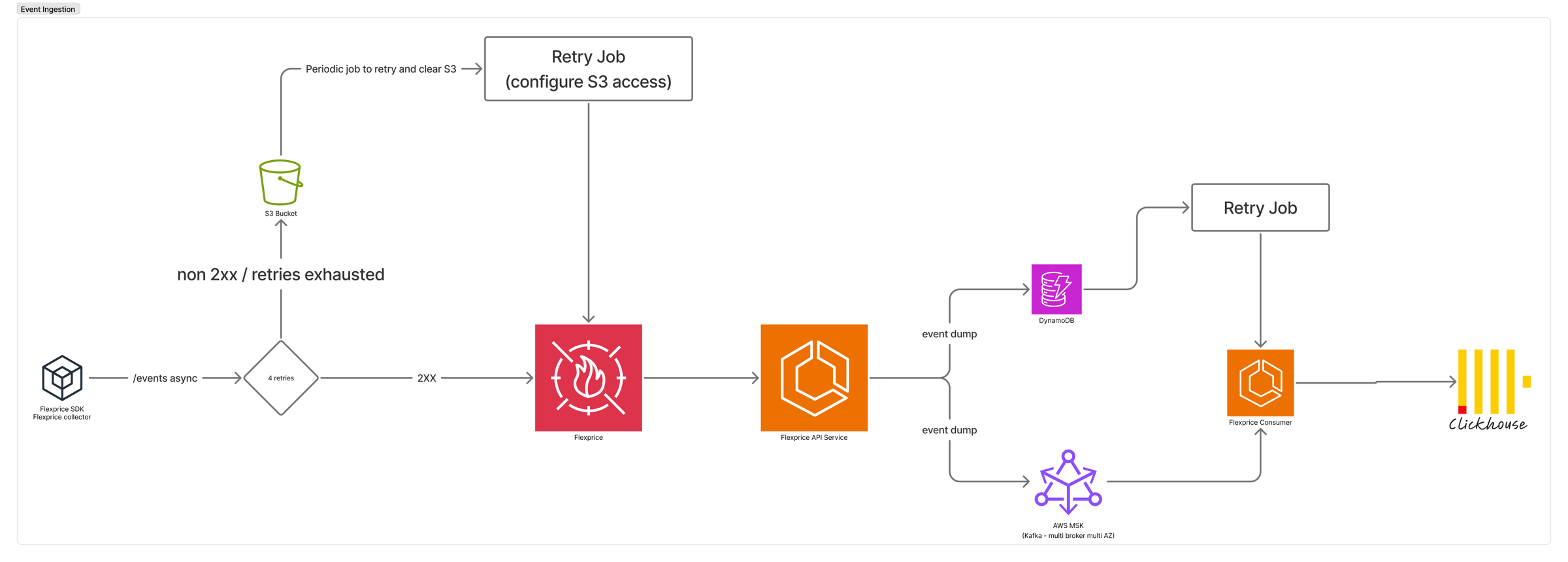
Reliability and failure modes
The pipeline is designed so that the failure of any one component degrades gracefully and loses nothing. Each stage is backed by an independent durable store that absorbs the failure of the stage after it.Data recovery and replay
Because events are the currency of the system, they are retained well beyond their processing lifetime. In Flexprice Cloud, events held in DynamoDB are retained for up to one year and then archived to S3, giving point-in-time replay across the entire window; self-hosted deployments achieve the same replay from Kafka’s retained log and S3 archival. If any downstream store is lost or corrupted, it can be rebuilt by replaying the retained events — no derived state is ever the only copy of anything.The degraded-mode S3 fallback and its retry jobs are an opt-in, per-customer configuration deployed for enterprise workloads. It requires granting Flexprice server-to-server read access to the bucket.
Real-time balances and alerting
The most latency-sensitive question in usage billing is does this customer have balance to perform this action? Flexprice answers it without forcing you onto its critical path.How balances are computed
Balances are never stored as a separate mutable number — they are derived from usage in ClickHouse. Every incoming event is rolled up into materialized views and pre-aggregated tables, so the current balance is a fast aggregation query rather than a running counter that can drift. The fetch-balance API lets the caller decide the freshness it needs. Rather than a fixed server-side TTL, the caller specifies a maximum acceptable age per request: if the cached value is within that age it is returned immediately from cache; if it is staler, the value is recomputed from ClickHouse. Critical surfaces — the billing page, the customer portal — always read the live value.Push-based alerts
Most customers never query Flexprice in their hot path at all. Every event enqueues a per-customer aggregation that fires at most once per customer per minute, and that single trigger drives:- Low-balance alerts
- Auto top-ups
- Entitlement-exhaustion alerts
has_balance flag per customer in their own Redis, updated from these alerts, and gate actions on that flag. Flexprice is never in the critical path of the decision.
Freshness guarantees
Service-level agreements
Flexprice publishes explicit availability and latency targets for the API service — the only internet-facing component — measured continuously and reported per region. Two operations carry their own latency objectives because they sit in the customer’s hot path: checking entitlement and wallet balance, and reporting usage measurements.Availability
Availability is measured per region in five-minute intervals as
1 − (failed requests ÷ total requests) against the API service, aggregated over a calendar month. Failed requests are server-side 5xx responses originating from Flexprice. The calculation excludes scheduled maintenance announced in advance, errors caused by client misuse (4xx, invalid payloads, throttling), and disruption outside Flexprice’s control. The contractual SLA and any associated service credits are defined in your agreement.
Latency targets
The balance check is the path most customers gate actions on. The ingestion target reflects the lightweight receive path described above: the API acknowledges after the durable write and defers enrichment off the Kafka stream. Response latency is distinct from balance freshness — how recently usage is reflected in the returned number — which is governed by the freshness tiers above, and can be tightened to sub-minute on enterprise dedicated deployments.
Multi-region and data residency
The architecture is multi-region by default, with stacks in US, India, and EU. Every component in a region is restricted to that region, and the managed dependencies are configured against the matching regional cloud. Data for a region is processed and stored only within it, which lets enterprise deployments satisfy residency requirements without bespoke engineering.Observability
The entire platform is OpenTelemetry-native and streams both traces and logs. You can point it at your own OTel-compatible provider, so Flexprice telemetry lands alongside the rest of your stack rather than in a silo. For enterprise deployments, the internal dashboards are shared as exportable definitions so you start with the same operational view the Flexprice team uses.Analytics and reconciliation
Billing systems live or die on whether their numbers can be independently verified. Flexprice exposes its data at several levels so you can reconcile however you prefer.Direct query access
Direct query access
ClickHouse (real-time event data) and PostgreSQL (subscriptions, invoices, configuration) are exposed over read-only connections to a BI tool such as Metabase, giving you full SQL access to build any reconciliation or analytics workflow.
Analytics API
Analytics API
A summarized customer-level view — usage, wallet balance, and the subscription, price, meter, feature, and line item every figure derives from — available out of the box without standing up a BI stack. The same API powers the built-in customer portal.
Scheduled exports
Scheduled exports
Hourly exports of processed event rows, fully enriched with their meter, feature, and price mappings, delivered to your S3 as CSV or JSON for ingestion into your own systems.
Full CRUD API surface
Full CRUD API surface
Every entity — meters, prices, features, customers, and more — exposes complete CRUD APIs. Any workflow Flexprice runs internally can be rebuilt on your side.
Deployment models
The same architecture is delivered three ways, with no divergence in code between them.Cloud
Fully managed, multi-region SaaS. Flexprice operates the entire stack.
Dedicated
A single-tenant deployment in your own infrastructure, operated to an agreed SLA. Identical architecture, isolated to you.
Self-hosted
Deploy with public Helm charts on Kubernetes, or on ECS. Open-source dependencies are bundled and can be swapped for your existing managed services.